斯坦福携手MIT发布巨大量级X光胸片数据集
今天,吴恩达发推公布了斯坦福发布的两个大型的医疗数据集公开:CheXpert和MIMIC-CXR。其中,CheXpert内含224316X光胸部图片,MIMIC-CXR内含371,920张带标签的图片。两个数据集的数据量级和标注精准度都非常高,可以说是造福了一大批相关从业者了。
数据集下载方式
先给出数据集介绍的地址和下载方式。
https://stanfordmlgroup.github.io/competitions/chexpert/

因为是医学数据集,斯坦福采取了相对谨慎的态度。根据说明,用户需要遵守下载规则,填写资料然后通过电子邮件给出的链接进行下载。为了保持数据集的完整性以及有效性,严禁进行“滥用”分享。
数据集概况
CheXpert数据集里面有224316张胸部X光图片,共涉及65,240名患者。数据集的时间跨度为2002年10月到2017年7月,都是患者在斯坦福医院进行胸部X光检查之后的留存。除此之外,数据集还附有相关的放射学报告。
如何为CheXpert数据集打标签
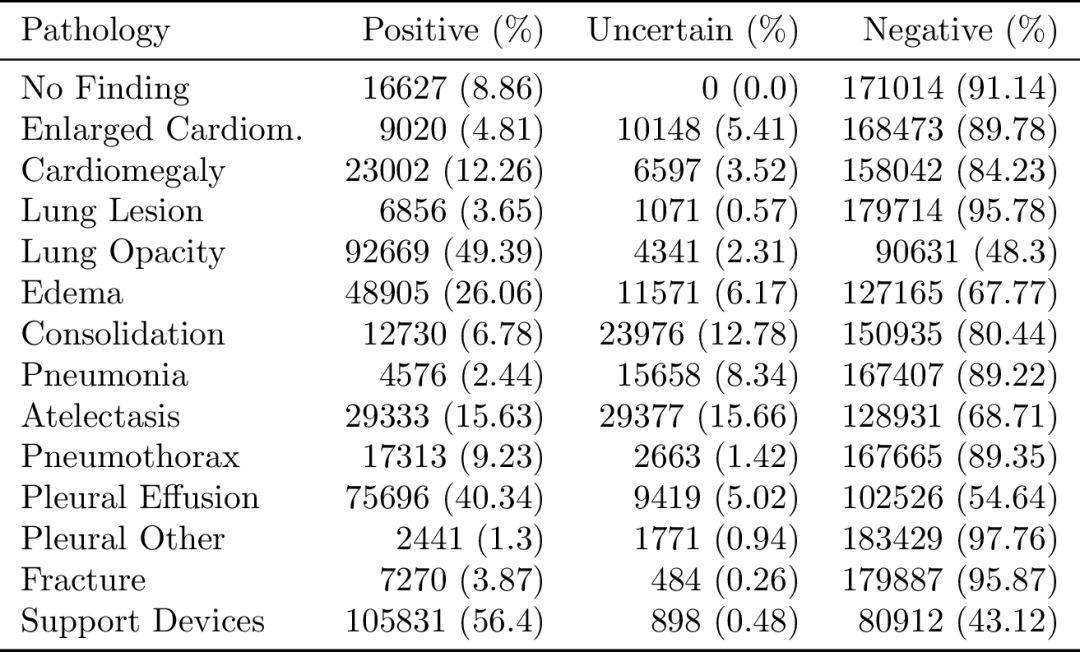
每份报告都对14项观察进行标记,标记可能是阳性,阴性或不确定性。
14项观察是根据报告中的流行程度和临床相关性确定的,并在适用的情况下符合Fleischner Society推荐的术语表。
此外,还开发了一种基于规则的自动贴标机,用于从放射学报告中提取观察结果,用作图像的结构化标签。贴标机工作分为三个不同的阶段:提及提取,提及分类和提及聚合。
自动贴标机github地址:
https://github.com/stanfordmlgroup/chexpert-labeler
在提及提取阶段,贴标机从放射学报告的“印象”部分的观察列表中提取提及,这一部分总结了放射研究中的关键发现。在提及分类,则是用每一个提及来分类,把观察到的归类为阴性的,不确定的或阳性的。在提到聚合阶段,使用每次提及观察的分类,就会得到14个观察的最终标签。
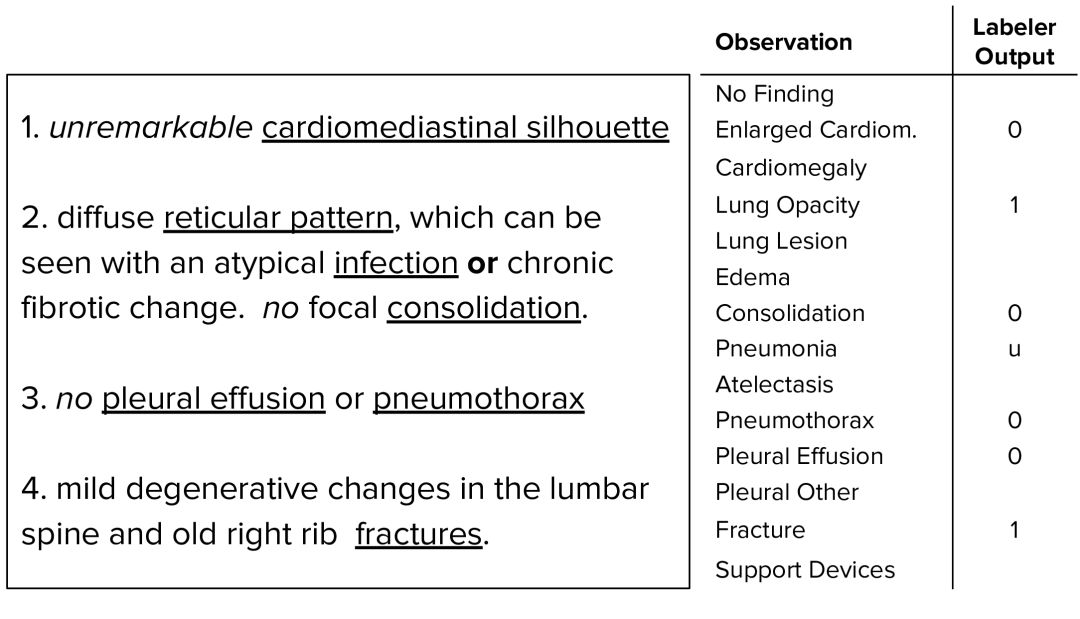
基准模型
基准模型采用以单视角胸片作为输入,并输出14次观测中每一次的概率。当多个视图可用的时候,模型给出最大概率。
利用不确定性标签
数据集中的训练数据集的标签分别为0、1或u。其中,0表示负,1表示正,u表示不确定。在模型训练中,使用了不确定性标签的不同方法。
U-Ignore:在训练期间忽略了不确定的标签。
U-Zeroes:将不确定标签的所有实例映射到0。
U-Ones:将不确定标签的所有实例映射到1。
U-SelfTrained:首先使用U-Ignore方法训练模型进行收敛,然后使用该模型进行预测,利用模型输出的概率预测重新标记每个不确定性标签。
U-MultiClass:将不确定性标签视为自己的类别。
专注于评估5项观察,进行“竞争任务”,根据临床经验和患病率分为:(a)肺不张,(b)心脏扩大,(c)肺实变,(d)水肿(e)胸腔积液。通过比较了不同不确定性方法在200个研究的验证集上的表现,其中三个放射科医师的注释作为基础事实。基准模型根据验证集上每个竞赛任务的最佳表现方法选择的:U- Ones用于肺不张和水肿,U-MultiClass用于心脏扩大和胸腔积液,U-SelfTrained用于肺实变。
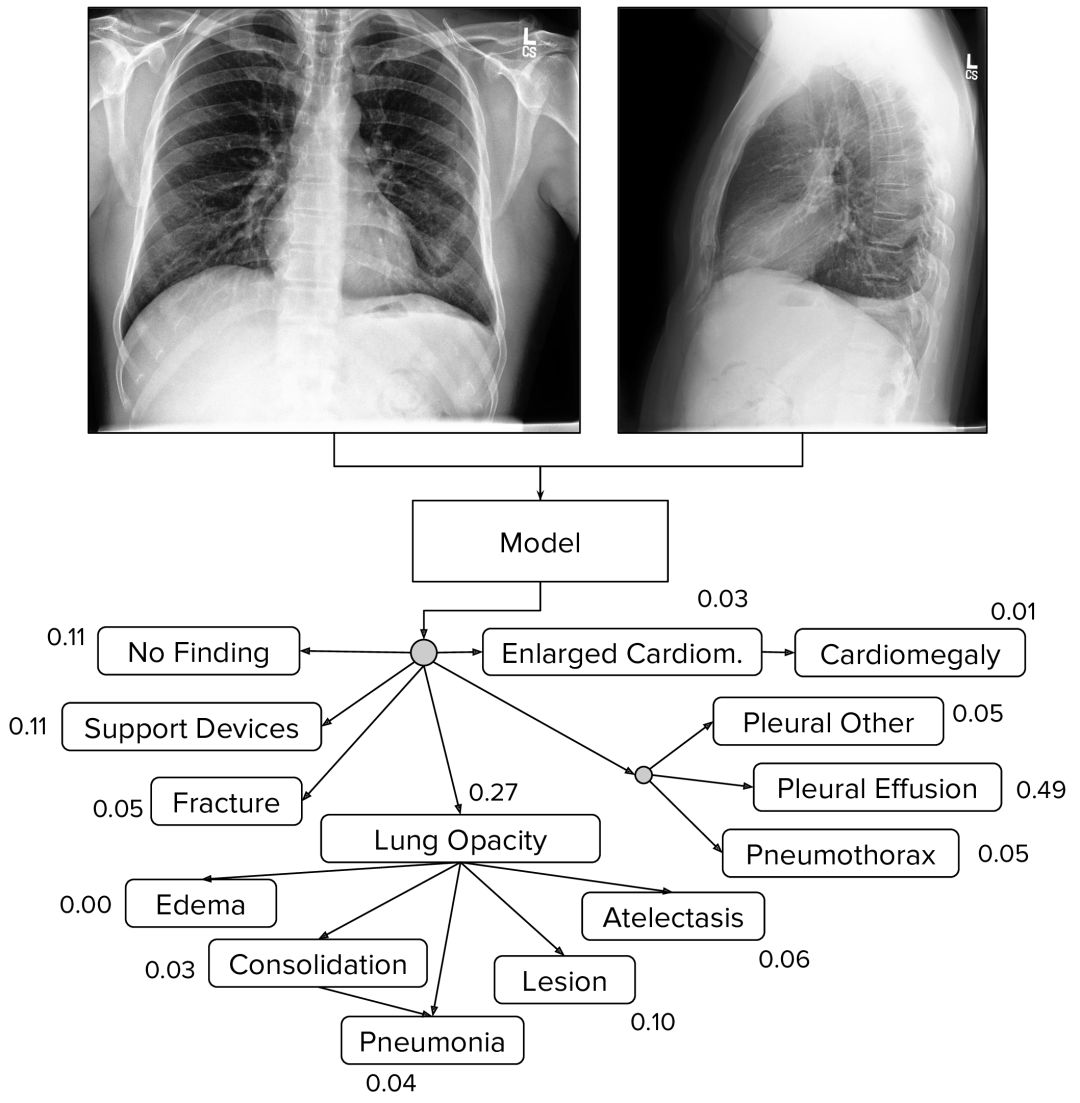
测试集如何设计
CheXpert中的测试集由来自500“未知”患者的500张X光胸片组成。八名权威认证的放射科医师分别对测试集中的每张图片进行了注释。他们将每张图片标记为:现存(present)、不确定(uncertain likely)、不可能(uncertain unlikely)和缺失(absent)。
然后将标签二值化,将现存和不确定病例视为阳性,而缺失和不可能病例视为阴性。根据5位专家的投票确定图片标签,然后用剩下的三位专家检验五位专家的表现。
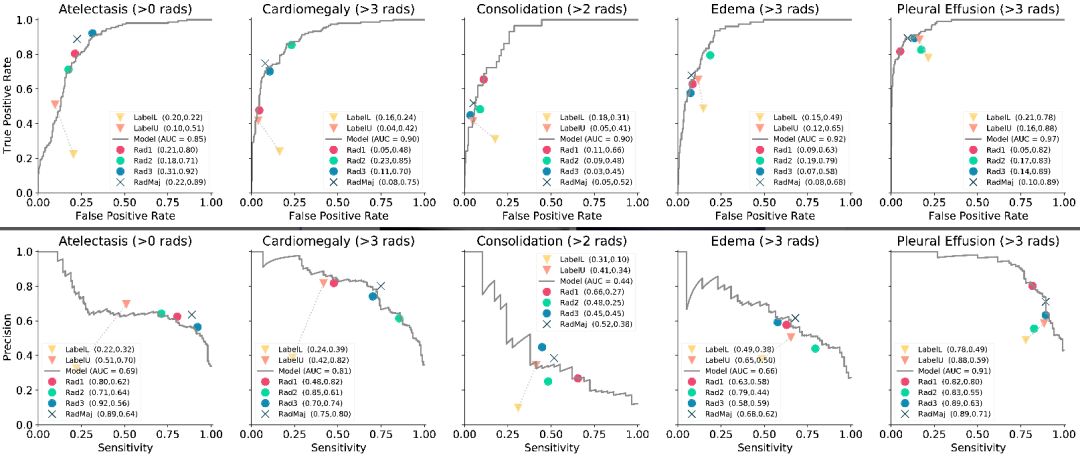
基准模型在测试集上表现如何
该模型在胸腔积液(0.97)上达到最佳AUC,在肺不张(0.85)上达到最差。所有其他观测的AUC至少为0.9。在心脏扩大,水肿和胸腔积液上,该模型比所有3位放射科医师获得更高的表现,但却不是他们的多数投票。在肺实变方面,模型性能超过3位放射科医师中的2位,而在Atelectasis上,所有3位放射科医师的表现均优于模型。
与麻省理工学院的联合发布MIMIC-CXR数据集
此外还有和MIMIC-CXR共同发布包含371,920张胸部X射线图片的大型数据集。该数据集的时间跨度为2011年~2016年。这些数据与Beth Israel Deaconess医疗中心的227,943个影像学研究相关。每个成像研究可能包含一个或多个图像,但一般是两个图像:正面视图和侧视图。
相关论文下载地址:https://arxiv.org/pdf/1901.07042.pdf
图像提供有14个标签,这些标签来自放射学报告的自然语言处理工具。CheXpert数据集和MIMIC-CXR共享一个共同的贴标机,CheXpert贴标机,用于从放射学报告中获取相同的标签集。
最后展望
阻碍胸部X光片解释模型发展之一是,缺乏具有强放射学家注释的地面真实性和专家评分的数据集。研究人员可以根据这些数据对其模型进行比较。希望CheXpert将填平这一沟谷,以便在临床重要任务中随时跟踪模型的进展。
此外,吴恩达团队本次开发并开源了CheXpert贴标机,这是一种基于规则的自动贴标机,用于从自由文本放射学报告中提取观察结果,用作图像的结构化标签。我们希望这可以帮助其他机构轻松地从报告中提取结构化标签,并发布其他大型数据库,以便对医学成像模型进行跨机构测试。
最后,斯坦福也作出展望,希望该数据集能够帮助开发和验证胸部X光片解释模型,以改善全球医疗服务的获取和交付。



